This notebook was originally published on https://www.kaggle.com/joatom/model-allocation.
In this notebook I experiment with two ensembling strategies.
There are many ways to combine different models to improve predictions. A common technique for regression tasks is taking a weighted average of the model predictions (y_pred = (m1(x)*w1 + ... + mn(x)*wn) / n). Another common technique is building a meta model, that is trained on the models’ outputs.
The first chapter starts with a simple linear combination of two models. And we explore with an simple example, why ensembling actually works. These insights will lead, in the second chapter, to the first technique on how to choose weights for a linear ensemble by using residual variance. In the third chapter an alternative for the weight selection is examined. This second technique is inspired by portfolio theory (a theory to combine financial assets). In the fourth chapter the two techniques are applied and compared on the Tabular Playground Series (TPS) - Aug 2021 competition. Finaly cross validation (CV) and leaderboard (LB) Scores are listed in the fith chapter.
Note
For the ease of explanation we make some simplifying assumptions, such as equal distribution of the data, same distribution on unseen data, … (just think of a vanilla world).
1. Why ensembling works
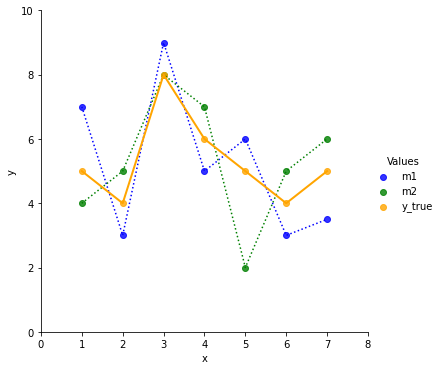
Suppose there are two fitted regression models and they predict values like shown in the first chart.
To get a better intuition on how good the two models fit the ground truth, we plot the residuals y_true(x)-m(x).
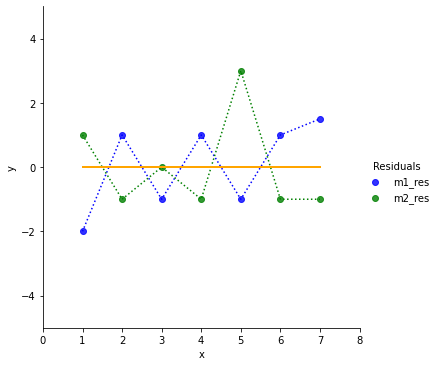
If we had to choose one of the models, which one would we prefer? Model 2 does better on the first data point and perfect on the third, but it contains an outlier the 5th data point.
Let’s look at the mean and the variance of the residuals.
Model #1. mean: 0.0714, var: 1.6020
Model #2. mean: 0.0000, var: 2.0000On the long run Model2 has an average residual of 0. Model 1 carries along a residual of 0.0714. So on average Model 2 seams to do better.
But Model 2 also has a higher variance. That implies we have a great chance to do a great prediction (e.g. x=3) but we also have high risk to screw the prediction (e.g. x=5).
Now we build a simple linear ensemble of the two models like ens = 0.5 * m1 + 0.5 m2.
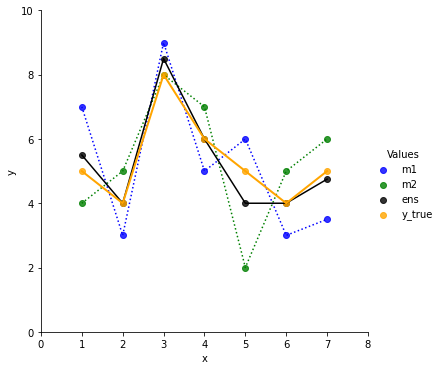
The ensemble line is closer to the true values. It also looks smoother then m1 and m2.
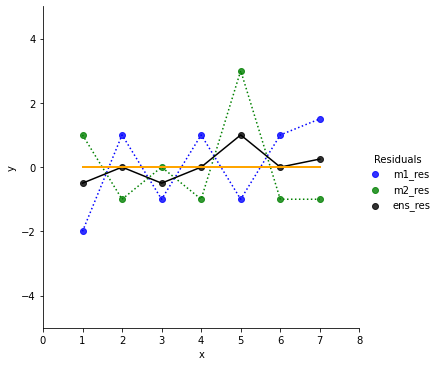
In the residual chart we can see that the ensemble does a bit worse for x=3 compared to Model 2. But it also decreases the residuals for the outliers (points 1, 5, 7).
Let’s check the stats:
Ensemble. mean: 0.0357, var: 0.2219We dramatically reduced the variance, hence reduced the risk/chance. The mean value is now in between Model 1 and Model 2.
Finally let’s play around with the model weights in the ensemble and check how mean and variance change.
# generate weights for w1
weight_m1 = np.linspace(0, 1, 30)
ens_mean = np.zeros(30)
ens_var = np.zeros(30)
for i, w1 in enumerate(weight_m1):
# build ensemble for different weights
ens = m1*w1 + m2*(1-w1)
ens_res = y_true - ens
# keep track of mean and var of the differently weighted ensembles
ens_mean[i] = ens_res.mean()
ens_var[i] = ens_res.var()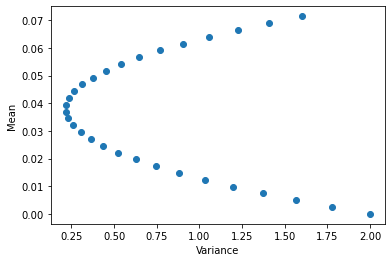
With the previous 50:50 split the variance seems almost at the lowest point. So we only get a reduction of the mean below 0.0357 if we allow the ensemble to have more variance, hence take more risk.
2. Weights by residual variance
Since the Model 1 and Model 2 are well fitted, their average residuals are pretty close to 0. So let’s focus on reducing our variance to avoid surprises on later later predictions.
We now solve for the optimal weights that minimizes the variance of the residual of our ensemble with this function:
fun = lambda w: (y_true-np.matmul(w, preds)).var()We also define a constraint so that the w.sum() == 0:
# w.sum() = 1 <=> 0 = w.sum()-1
cons = ({'type': 'eq', 'fun': lambda w: w.sum()-1})If you want, you can also set bounds, so that the weights want be negative.
I don’t. I like the idea of going short with a model. And negative weights really increase the results of TPS predictions in chapter 4.
bnds = ((0,None),
(0,None),
(0,None),
(0,None),
(0,None))Now, we are all set to retrieve the optimal weights.
# predictions of Model1 and Model 2
preds = np.array([m1, m2])
# init weights
w_init = np.ones(preds.shape[0])/preds.shape[0]
# run optimization
res = scipy.optimize.minimize(fun, w_init, method='SLSQP', constraints=cons) #,bounds=bnds
# get optimal weights
w_calc = res.x
print(f'Calculated weights: {w_calc}')Calculated weights: [0.53150242 0.46849758]Let’s see how the calculated weights perform.
ens_ex1 = np.matmul(w_calc, preds)
ens_ex1_res=y_true-ens_ex1
print(f'Ensemble Ex1. mean: {ens_ex1_res.mean(): .4f}, var: {ens_ex1_res.var(): .4f}')Ensemble Ex1. mean: 0.0380, var: 0.2157We con compare the results with the first ensemble 50:50 split. With the calculated weights we could further reduce the variance of the model (0.2219 -> 0.2157). But unfortunately the mean increased a bit (0.0357 -> 0.0380).
We see the trade off between mean and variance and have to decide if we prefer a more stable model or take some risk for better results.
3. Portfolio theory for ensembling
In finance different assets are often combined in a portfolio. There are many criteria for the asset selection/allocation. One of them is by choosing a risk strategy. In 1952 the economist Harry Markowitz defined a Portfolio Selection strategy which built the foundation of many portfolio strategies to come. There is a great summary on Wikipidia, but the original paper can also be found with a google search.
So, what it is all about. Let’s assume we are living in an easy, plain vanilla world. We want to build a portfolio that yields high return with low risk. That’s not easy. If we only buy stocks of our favorite fruit grower, a rainy summer would result in a low return. Wouldn’t it be smart to also buy stocks of a raincoat producer, just in case. But what if the summer was sunny, then we would have rather invested the entire money in fruits instead of raincoats. It’s clearly a trade off. Either we lower the risk of loosing money in a rainy summer and invest in both (fruits and raincoats). Or we take the risk investing all money in fruits to maybe gain more money. And if we lower the risk, in which raincoat producer should we invest? The one with the bumpy stock price or the one with a steady, but slowly growing stock price.
Now, we already see the first similarities between our ensemble example above and the Portfolio Theory. Risk can be measured through variance and a good return of our ensemble is results in a low expected residual.
But there is even more in Portfolio Theory. It also takes dependencies between assets into account. If the summer is sunny the fruit price goes up and the raincoat price goes down, they are somewhat negative correlated.
Since we expect the average residual of our fitted models to be close to 0 and we build a linear model, we can expect our ensemble average residual also to be close to 0. Therefore, we focus on optimizing the portfolio variance, which can be boiled down to Var_p = w'*Cov*w. The covariance measures the dependency between combined models and also considers the variance.
What data can we actually use? In the financial example returns are the increase or decrease of an asset price (p/p_t-1), hence we are looking on returns for a certain period of time. In ML we can take our out-of-fold (oof) predictions and calculate the residuals from the train targets to build a dataset.
Can we do this despite we are looking at a time-series in the financial example? Yes, in this basic portfolio theory we don’t take time dependencies into account. But it’s important to keep the same order for the different asset returns for correlation/covariance calculation. We want to compare the residual of model 1 and 2 for always the same data item.
The optimization function for the second ensemble technique is:
## following https://en.wikipedia.org/wiki/Modern_portfolio_theory
# Predictions of Model 1 and Model 2
preds = np.array([m1,m2])
# Residuals of Model 1 and Model 2
preds_res = np.array([m1_res, m2_res])
# handle residuals like asset returns
R = np.array(preds_res.mean(axis=1))
# factor by which R is considered during optimization. turned off for our example
q = 0 #-1
# covariance matrix of model residuals
CM = np.cov(preds_res)
# optimization function
fun = lambda w: np.matmul(np.matmul(w.T,CM),w) - q * np.matmul(R,w)
# constraint: weights must sum up to 1.0
cons = ({'type': 'eq', 'fun': lambda x: x.sum()-1})Run the optimization.
# init weights
w_init = np.ones(preds.shape[0])/preds.shape[0]
# run optimization
res = scipy.optimize.minimize(fun, w_init, method='SLSQP', constraints=cons) #,bounds=bnds
# get optimal weights
w_calc = res.x
print(f'Calculated weights: {w_calc}')Calculated weights: [0.53150242 0.46849758]The weights are the same as in the first technique. That really surprised me. And I run a couple of examples with different models. But the weights were only slightly different between the two techniques.
4. Ensembling TPS Aug 2021
Now that we have to techniques to ensemble, let’s try them on the TPS August 2021 data.
We do a 7 kfold split and calculate the residuals on the out-of-fold-predictions, that are used for validation. We train 7 regression models with different architecture so we get some diversity.
N_SPLITS = 7
SEED = 2021
PATH_INPUT = '/home/kaggle/TPS-AUG-2021/input/'# load and shuffle
test = pd.read_csv(PATH_INPUT + 'test.csv')
train = pd.read_csv(PATH_INPUT + 'train.csv').sample(frac=1.0, random_state = SEED).reset_index(drop=True)
train['fold_crit'] = train.loss
train.loc[train.loss>=39, 'fold_crit']=39target = 'loss'
fold_crit = 'fold_crit'
features = list(set(train.columns)-set(['id','kfold','loss','fold_crit']+[target]))# apply abhisheks splitting technique
skf = StratifiedKFold(n_splits = N_SPLITS, random_state = None, shuffle = False)
train.kfold = -1
for f, (train_idx, valid_idx) in enumerate(skf.split(X = train, y = train[fold_crit].values)):
train.loc[valid_idx,'kfold'] = f
train.groupby('kfold')[target].count()kfold
0.0 35715
1.0 35715
2.0 35714
3.0 35714
4.0 35714
5.0 35714
6.0 35714
Name: loss, dtype: int64# define models
models = {
'LinReg': LinearRegression(n_jobs=-1),
'HGB': HistGradientBoostingRegressor(),
'XGB': XGBRegressor(tree_method = 'gpu_hist', reg_lambda= 6, reg_alpha= 10, n_jobs=-1),
'KNN': KNeighborsRegressor(100, n_jobs=-1),
'BayesRidge': BayesianRidge(),
'ExtraTrees': ExtraTreesRegressor(max_depth=2, n_jobs=-1),
'Poisson': Pipeline(steps=[('scale', StandardScaler()),
('pois', PoissonRegressor(max_iter=100))])
}
Fit models and save oof predictions.
for (m_name, m) in models.items():
print(f'# Model:{m_name}\n')
train[m_name + '_oof'] = 0
test[m_name] = 0
y_oof = np.zeros(train.shape[0])
for f in range(N_SPLITS):
train_df = train[train['kfold'] != f]
valid_df = train[train['kfold'] == f]
m.fit(train_df[features], train_df[target])
oof_preds = m.predict(valid_df[features])
y_oof[valid_df.index] = oof_preds
print(f'Fold {f} rmse: {mean_squared_error(valid_df[target], oof_preds, squared = False):0.5f}')
test[m_name] += m.predict(test[features]) / N_SPLITS
train[m_name + '_oof'] = y_oof
print(f"\nTotal rmse: {mean_squared_error(train[target], train[m_name + '_oof'], squared = False):0.5f}\n")
oof_cols = [m_name + '_oof' for m_name in models.keys()]
print(f"# ALL Mean ensemble rmse: {mean_squared_error(train[target], train[oof_cols].mean(axis=1), squared = False):0.5f}\n") # Model:LinReg
Fold 0 rmse: 7.89515
Fold 1 rmse: 7.90212
Fold 2 rmse: 7.90260
Fold 3 rmse: 7.89748
Fold 4 rmse: 7.89844
Fold 5 rmse: 7.89134
Fold 6 rmse: 7.89643
Total rmse: 7.89765
# Model:HGB
Fold 0 rmse: 7.86447
Fold 1 rmse: 7.87374
Fold 2 rmse: 7.86688
Fold 3 rmse: 7.86255
Fold 4 rmse: 7.86822
Fold 5 rmse: 7.85785
Fold 6 rmse: 7.86566
Total rmse: 7.86563
# Model:XGB
Fold 0 rmse: 7.91179
Fold 1 rmse: 7.92748
Fold 2 rmse: 7.92141
Fold 3 rmse: 7.91901
Fold 4 rmse: 7.91125
Fold 5 rmse: 7.90286
Fold 6 rmse: 7.92340
Total rmse: 7.91675
# Model:KNN
Fold 0 rmse: 7.97845
Fold 1 rmse: 7.97709
Fold 2 rmse: 7.98165
Fold 3 rmse: 7.97895
Fold 4 rmse: 7.97781
Fold 5 rmse: 7.97798
Fold 6 rmse: 7.98711
Total rmse: 7.97986
# Model:BayesRidge
Fold 0 rmse: 7.89649
Fold 1 rmse: 7.90576
Fold 2 rmse: 7.90349
Fold 3 rmse: 7.90007
Fold 4 rmse: 7.90121
Fold 5 rmse: 7.89455
Fold 6 rmse: 7.89928
Total rmse: 7.90012
# Model:ExtraTrees
Fold 0 rmse: 7.93239
Fold 1 rmse: 7.93247
Fold 2 rmse: 7.92993
Fold 3 rmse: 7.93121
Fold 4 rmse: 7.93129
Fold 5 rmse: 7.93247
Fold 6 rmse: 7.93364
Total rmse: 7.93191
# Model:Poisson
Fold 0 rmse: 7.89597
Fold 1 rmse: 7.90240
Fold 2 rmse: 7.90233
Fold 3 rmse: 7.89682
Fold 4 rmse: 7.89873
Fold 5 rmse: 7.89241
Fold 6 rmse: 7.89701
Total rmse: 7.89795
# ALL Mean ensemble rmse: 7.88061
Let’s a look at the correlation heatmap.
oof_cols = [m_name + '_oof' for m_name in models.keys()]
oofs = train[oof_cols]
oof_diffs = oofs.copy()
for c in oof_cols:
oof_diffs[c] = oofs[c]-train[target]
oof_diffs[c] = oof_diffs[c]#**2
sns.heatmap(oof_diffs.corr())<AxesSubplot:>
XGB and KNN are most diverse, so I export a 50:50 ensemble. I’ll also export an equally weighted ensemble of all models and HGB only because it is the best single model.
CV: ALL equaly weighted: 7.880605075536334
CV: XGB only: 7.916746570344035
CV: HGB only: 7.865625158180185
CV: XGB and LinReg (50:50): 7.872064005057903
CV: XGB and KNN (50:50): 7.893210466099108Next we inspect the variance and mean of the residuals. Means are close to 0, as expected.
oof_diffs.var(), oof_diffs.mean()(LinReg_oof 62.373163
HGB_oof 61.868296
XGB_oof 62.675125
KNN_oof 63.678431
BayesRidge_oof 62.412188
ExtraTrees_oof 62.915511
Poisson_oof 62.377910
dtype: float64,
LinReg_oof -0.000055
HGB_oof -0.003314
XGB_oof 0.001392
KNN_oof -0.005395
BayesRidge_oof -0.000024
ExtraTrees_oof -0.000136
Poisson_oof -0.000084
dtype: float64)These are the histograms of the residuals:
array([[<AxesSubplot:title={'center':'LinReg_oof'}>,
<AxesSubplot:title={'center':'HGB_oof'}>,
<AxesSubplot:title={'center':'XGB_oof'}>],
[<AxesSubplot:title={'center':'KNN_oof'}>,
<AxesSubplot:title={'center':'BayesRidge_oof'}>,
<AxesSubplot:title={'center':'ExtraTrees_oof'}>],
[<AxesSubplot:title={'center':'Poisson_oof'}>, <AxesSubplot:>,
<AxesSubplot:>]], dtype=object)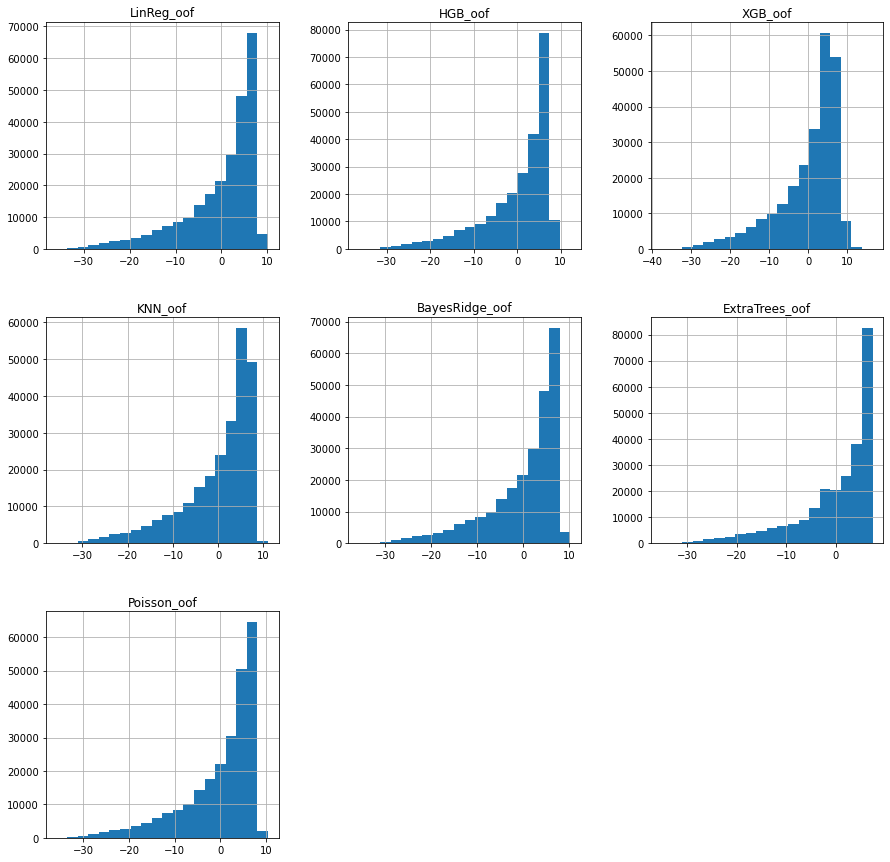
Finally, we apply the two techniques to calculate the ensembling weights
R = oof_diffs.mean().values
CM = oof_diffs.cov().values
q=0
# Var technique
fun_ex1 = lambda w: (train[target]-np.matmul(oofs.values, w)).var()
# Cov technique
fun_ex2 = lambda w: np.matmul(np.matmul(w.T,CM),w) - q * np.matmul(R,w)
cons = ({'type': 'eq', 'fun': lambda x: x.sum()-1})
bnds = ((0,None),
(0,None),
(0,None),
(0,None),
(0,None))# Example 1
w_init = np.ones((len(models)))/len(models)
res = scipy.optimize.minimize(fun_ex1, w_init, method='SLSQP', constraints=cons) #,bounds=bnds
w_calc = res.xCV: Ex1 calc weights: 7.85594426240217# Example 2
w_init = np.ones((len(models)))/len(models)
res = scipy.optimize.minimize(fun_ex2, w_init, method='SLSQP', constraints=cons) #,bounds=bnds
w_calc = res.xCV: Ex2 calc weights: 7.8559442629362315. Results
The competition metric is root mean squared error (RMSE). These are the scores of the different ensembles:
| Ensemble | CV | public LB |
|---|---|---|
| HGB only | 7.86563 | 7.90117 |
| All weights eq. | 7.88061 | 7.92183 |
| XGB and KNN (50:50) | 7.89321 | 7.91603 |
| Ex1 (Var) | 7.85594 | 7.88876 |
| Ex2 (Cov) | 7.85594 | 7.88876 |
References
- Modern Portfolio Theory: https://en.wikipedia.org/wiki/Modern_portfolio_theory
- TPS August 2021 Competition: https://www.kaggle.com/c/tabular-playground-series-aug-2021/overview
Ressources
- Original notebook: https://www.kaggle.com/joatom/model-allocation
- TPS data: https://www.kaggle.com/c/tabular-playground-series-aug-2021/data